معرفی فرهنگ Postmortem در DevOps-SRE
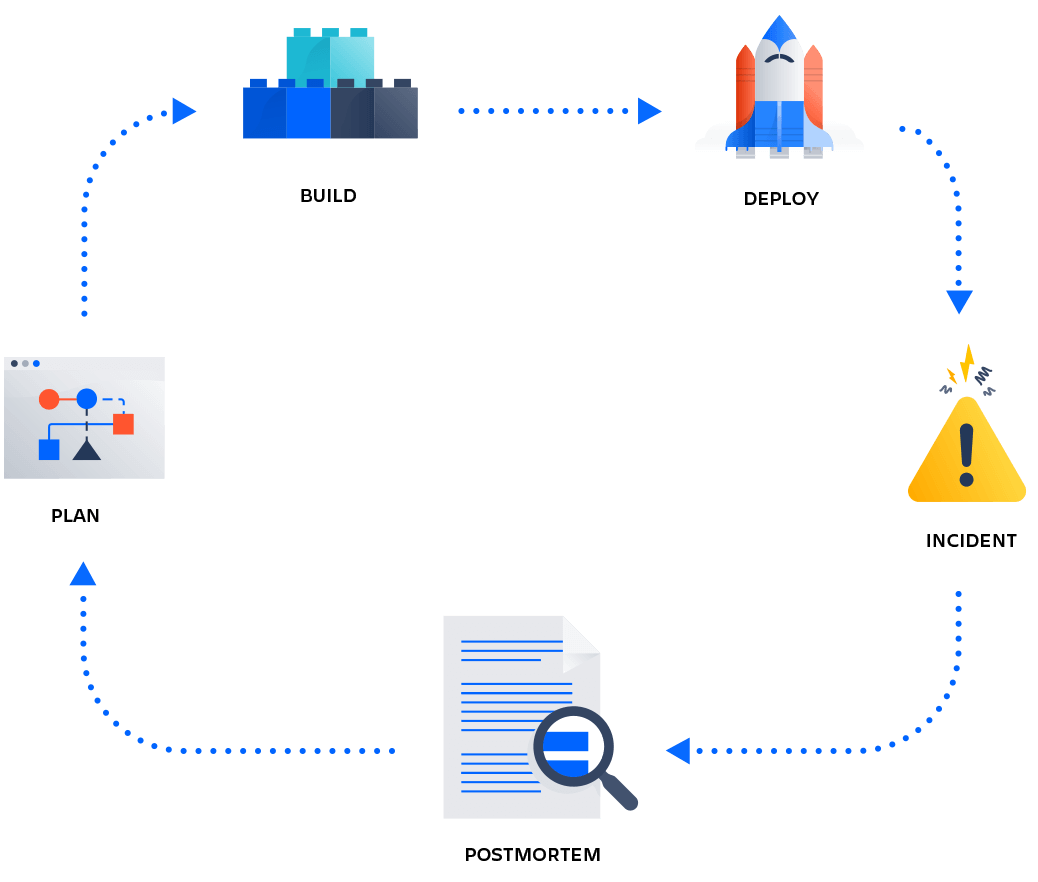
DevOps Postmortems: چرا و چگونه از آنها استفاده کنیم
وقتی همه چیز اشتباه می شود، همانطور که گاهی اوقات اتفاق می افتد، مهم است که یک قدم به عقب بردارید و ارزیابی کنید که چرا و چگونه این کار را انجام دادند.
اشتباه کردن جزو جدا ناپذیر انسان است. برای اینکه مطمئن شویم از اشتباهات خود درس می گیریم و سازگار می شویم، نیاز به نظم و انضباط دارد. در این پست، انگیزه معرفی فرهنگ Postmortem ( تشریح حادثه بعد از وقوع)در سازمان DevOps شما را پوشش خواهیم داد. علاوه بر این، ما این را با مثالی از نحوه اجرای Postmortem( تشریح حادثه بعد از وقوع) در تیم DevOps/SRE تکمیل خواهیم کرد.
چرا به انضباط Postmortem نیاز دارم؟
همانطور که می دانیم، تغییرات در سیستم باعث ایجاد ناپایداری هایی می شود که باعث بروز حوادث می شود. مهاجرت به DevOps به سازمانها در سرتاسر جهان این امکان را میدهد که با افزایشهای کوچکتر و با فرکانس بیشتر منتشر کنند. این باعث کاهش خطر شکست در یک نسخه خاص می شود. از سوی دیگر، افزایش تعداد انتشارها لزوماً تعداد حوادثی را که تیم های آماده به کار باید به آنها پاسخ دهند کاهش نمی دهد. مسئولیت اصلی تیم واکنش به حادثه، تعیین کمیت و در صورت لزوم کاهش تأثیر است. در نتیجه، سرویس به شرایط عملیاتی عادی باز می گردد. تجزیه و تحلیل علت اصلی و اجرای اقدامات پیشگیرانه به این فرآیند تعلق ندارد. حال اگر چنین یادگیری و تحلیلی صورت نگیرد، علل ریشه ای درمان نشده و اقدامات پیشگیرانه اجرا نمی شود. نتیجه: حوادث شروع به افزایش می کنند و خطاهای آبشاری بخشی از روال هفتگی می شوند. در نهایت، مدت زمانی که یک تیم DevOps برای پاسخگویی به حادثه صرف میکند، با کیفیت خدمات رو به کاهش، بزرگتر و بزرگتر میشود.
انجام Postmortem
برای جلوگیری از چنین مارپیچ مرگ، تیم شما باید نیاز به درس گرفتن از گذشته را برای ساختن آینده ای بهتر بپذیرد. این فرآیند یادگیری Postmortem ( تشریح حادثه بعد از وقوع) نامیده می شود. Postmortem باید هر زمان که یک حادثه نیاز به پاسخ از یک مهندس در حال تماس دارد، آغاز شود. یک Postmortem معمولی با ثبت شواهد عینی شروع می شود:
-
ماشه حادثه Trigger for the incident
-
تاثیر حادثه Impact of the incident
-
زمان شناسایی و کاهش آن Time to detect and mitigate
-
اقدامات انجام شده برای کاهش Steps taken to mitigate
-
تحلیل علل ریشه ای Root cause analysis
بر اساس شواهد فوق، باید تجزیه و تحلیل انجام شود. تجزیه و تحلیل معمولاً توسط یکی از اعضای تیم در حال تماس انجام می شود که به حادثه پاسخ داده است و ممکن است شامل سایر اعضای تیم نیز باشد که به کاهش یا تجزیه و تحلیل علت اصلی کمک کرده اند. فرآیند تحلیل نیاز به یافتن پاسخ برای سوالات زیر دارد:
Trigger
چه تعداد هشدار برای این حادثه دریافت کردیم؟ آیا ماشه به موقع بود یا می توانستیم آن را زودتر ثبت کنیم؟
تأثیر Impact
آیا ضربه در وهله اول برای ایجاد یک حادثه کافی بود؟ یا باید ماشه ها را کالیبره کنیم؟
آیا اقداماتی برای کاهش تأثیر کافی انجام شد و آیا آنها این روند را دنبال کردند؟ اگر نه، آیا باید روی آموزش سرمایه گذاری کنیم یا دستورالعمل ها را بهبود ببخشیم؟
آیا ما به اندازه کافی سریع توانستیم تاثیر را کاهش دهیم؟
آیا کاری وجود دارد که بتوانیم برای کاهش زمان کاهش انجام دهیم؟
علت ریشه ای Root cause
آیا علت اصلی حل خواهد شد یا باید با آن زندگی کنیم؟
اگر علت اصلی برطرف شود، برای رفع آن دقیقاً چه کاری باید انجام دهیم؟
بر اساس تجزیه و تحلیل، باید خلاصه ای از جمله درس های آموخته شده و کارهای بعدی ثبت و اولویت بندی شود. وظایف بعدی معمولاً عبارتند از:
وظایف مهندسی برای حل علت اصلی
وظایف مهندسان DevOps برای بهبود تنظیمات نظارت
وظایف مدیران برای بهبود فرآیندها
معرفی Postmortem
معرفی Postmortem به سازمانی که از لحاظ تاریخی هیچ اقدامی انجام نداده است آنقدرها هم که به نظر می رسد آسان نیست. مانند هر فرآیند جدید یا در حال تغییر، معرفی و تداوم تغییر نیازمند زمان و تلاش در تمام سطوح سازمان است. با این حال، چند اصل کلیدی وجود دارد که پیروی از آنها تغییر را آسان تر می کند:
مطمئن شوید که از سرزنش و انگشت نشان دادن دوری کنید stay away from blame games and finger pointing.
این مهم ترین جنبه برای خارج کردن همه چیز از دروازه است. اگر تجزیه و تحلیل به جای اطمینان از یادگیری و بهبود تیم، بر سرزنش افراد مسبب حادثه متمرکز شود، این ابتکار به جای خیر، باعث آسیب خواهد شد. یک سرنخ اختصاصی تعیین کنید، و هر یک از واکنش های حادثه را برای پایان دادن به پس از مرگ مجبور کنید. این افراد معمولاً از تیمهای DevOps/on-call میآیند و اغلب خودشان رهبران تیم هستند. همکاری کنید و به اشتراک بگذارید. مطمئن شوید که Postmortem را در رسانه ای مناسب برای اشتراک گذاری و یادگیری، مانند ویکی ها، ضبط کنید. از Postmortem ماه گذشته به عنوان مواد آموزشی منظم برای تیم خود استفاده کنید. اجازه همکاری و اظهار نظر در طول و بعد Postmortem را بدهید.
مدیریت را درگیر کنید. نشان دادن حمایت مدیریت باعث می شود که بشارت و آموزش در میان مهندسان آسان تر شود. برای درگیر نگه داشتن مدیریت، از قبل با اهداف برنامه ریزی کنید و پیشرفت را در مسیر نشان دهید. می دانید، مدیران چیزی بیشتر از نمودارهایی که به سمت بالا و به سمت راست هستند، دوست ندارند.
از کوچک شروع کنید. اگر سازمان بزرگ باشد، فقط با چند سرویس و یک تیم شروع کنید تا نمونه ای بسازید که سایر تیم ها را برای پیروی از آن ترغیب کند. تیم اولیه که پیروزی های خود را جشن می گیرد اغلب برای پیوستن سایر تیم ها به باند کافی است.
معرفی تغییر بدون داشتن نمونه مثبت از داخل سازمان بسیار سخت تر است.
چک لیست Postmortem
ما چک لیستی از سوالاتی که باید از خود بپرسید تا Postmortem خود را به بهترین شکل ممکن انجام دهید، آماده کرده ایم.
- تشخیص
- تأثیر
تاثیر بر کاربران نهایی
تاثیر بر بهره وری
تاثیر بر زیرساخت ها
- کاهش
زمان کاهش
مرحله کاهش شماره 1
مرحله کاهش شماره 2
- تحلیل علل ریشه ای
درس های آموخته شده
پیگیری ها وظیفه شماره 1 (تشخیص / کاهش / پردازش)
وظیفه شماره 2 (تشخیص / کاهش / پردازش)
وظیفه شماره 3 (تشخیص / کاهش / پردازش)
یک فرهنگ Postmortem خوب فقط به اندازه تیم و ابزارهای موجود قوی است. نظارت بر کاربر واقعی می تواند به شما کمک کند تشخیص دهید که چه تعداد مشتری تحت تأثیر یک مشکل قرار گرفته اند، چه مدت بر آنها تأثیر گذاشته است و این اشکال کجاست. با داشتن این اطلاعات، فرهنگ Postmortem شما سریعتر و قوی تر خواهد شد.
منبع : https://dzone.com/articles/devops-postmortems-why-and-how-to-use-them