راهنمای کامل برای ELK
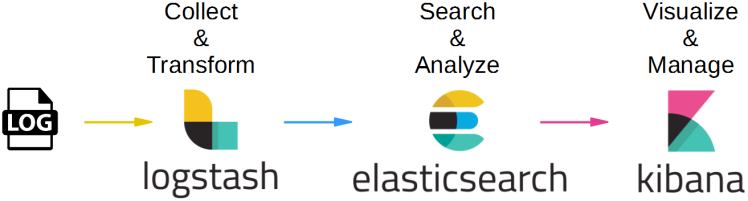
ELK Stack چیست؟
تا یک یا دو سال پیش، ELK Stack مجموعهای از سه محصول منبع باز - Elasticsearch، Logstash و Kibana - بود که همگی توسط Elastic توسعه، مدیریت و نگهداری میشدند. معرفی و متعاقب آن اضافه شدن Beats، پشته را به یک پروژه چهار عضو تبدیل کرد. Elasticsearch یک موتور جستجو و تجزیه و تحلیل متن باز و متن باز است که بر اساس موتور جستجوی آپاچی لوسن ساخته شده است. Logstash یک جمعآوری گزارش است که دادهها را از منابع ورودی مختلف جمعآوری میکند، تبدیلها و بهبودهای مختلف را اجرا میکند و سپس دادهها را به مقصدهای خروجی مختلف پشتیبانی میکند. Kibana یک لایه تجسم است که در بالای Elasticsearch کار می کند و به کاربران امکان تجزیه و تحلیل و تجسم داده ها را می دهد. و آخرین اما نه کماهمیت - بیتها عوامل سبک وزنی هستند که روی میزبانهای لبه نصب میشوند تا انواع مختلف دادهها را برای ارسال به پشته جمعآوری کنند. با هم، این اجزای مختلف معمولاً برای نظارت، عیبیابی و ایمنسازی محیطهای IT استفاده میشوند (اگرچه موارد استفاده بیشتری برای ELK Stack مانند هوش تجاری و تجزیه و تحلیل وب وجود دارد). Beats و Logstash از جمعآوری و پردازش دادهها مراقبت میکنند، Elasticsearch دادهها را فهرستبندی و ذخیره میکند، و Kibana یک رابط کاربری برای جستجوی دادهها و تجسم آنها فراهم میکند.چرا ELK بسیار محبوب است؟
ELK Stack محبوب است زیرا نیازی را در فضای مدیریت گزارش و تجزیه و تحلیل برآورده می کند. نظارت بر برنامههای کاربردی مدرن و زیرساختهای فناوری اطلاعات که بر روی آنها مستقر شدهاند، نیازمند یک راهحل مدیریت گزارش و تجزیه و تحلیل است که مهندسان را قادر میسازد تا بر چالش نظارت بر محیطهای بسیار پراکنده، پویا و پر سر و صدا غلبه کنند. ELK Stack با ارائه یک پلت فرم قدرتمند به کاربران کمک می کند که داده ها را از چندین منبع داده جمع آوری و پردازش می کند، این داده ها را در یک فروشگاه داده متمرکز ذخیره می کند که می تواند با رشد داده ها مقیاس شود، و مجموعه ای از ابزارها را برای تجزیه و تحلیل داده ها فراهم می کند. البته ELK Stack منبع باز است. با توجه به اینکه سازمان های فناوری اطلاعات از محصولات منبع باز حمایت می کنند، این به تنهایی می تواند محبوبیت پشته را توضیح دهد. منبع باز همچنین به معنای یک جامعه پر جنب و جوش است که دائماً ویژگی ها و نوآوری های جدید را هدایت می کند و در صورت نیاز کمک می کند. مطمئنا، Splunk مدتها پیش از این بازار در این فضا بوده است. اما عملکردهای متعدد آن به طور فزاینده ای ارزش قیمت گران را ندارند - به ویژه برای شرکت های کوچکتر مانند محصولات SaaS و استارت آپ های فناوری. Splunk حدود 15000 مشتری دارد در حالی که ELK بارها در یک ماه بیشتر از تعداد کل مشتریان Splunk دانلود می شود - و در آن زمان چندین برابر. ELK ممکن است همه ویژگی های Splunk را نداشته باشد، اما به آن زنگ ها و سوت های تحلیلی نیاز ندارد. ELK یک پلت فرم مدیریت لاگ و تجزیه و تحلیل ساده اما قوی است که هزینه آن کسری از قیمت است.چرا تجزیه و تحلیل گزارش مهم تر می شود؟
در دنیای رقابتی امروز، سازمان ها نمی توانند یک ثانیه از کار افتادگی یا عملکرد کند برنامه های خود را تحمل کنند. مسائل مربوط به عملکرد می تواند به یک برند آسیب برساند و در برخی موارد به ضرر مستقیم درآمد تبدیل شود. به همین دلیل، سازمانها نیز نمیتوانند به خطر بیفتند و رعایت نکردن استانداردهای نظارتی میتواند به جریمههای سنگینی منجر شود و به کسبوکار به اندازه یک مشکل عملکردی آسیب وارد کند. مهندسان برای اطمینان از اینکه برنامهها همیشه در دسترس، کارآمد و ایمن هستند، به انواع مختلف دادههای تولید شده توسط برنامههای کاربردیشان و زیرساختهایی که از آنها پشتیبانی میکند تکیه میکنند. این دادهها، چه گزارشهای رویداد یا معیارها، یا هر دو، نظارت بر این سیستمها و شناسایی و حل مشکلات را در صورت وقوع امکانپذیر میسازد. لاگ ها همیشه وجود داشته اند و به همین ترتیب ابزارهای مختلف برای تجزیه و تحلیل آنها موجود است. با این حال، آنچه تغییر کرده است، معماری زیربنایی محیطهایی است که این گزارشها را تولید میکنند. معماری به میکروسرویسها، کانتینرها و زیرساختهای ارکستراسیون مستقر در ابر، در میان ابرها یا در محیطهای ترکیبی تکامل یافته است. نه تنها این، حجم عظیم داده های تولید شده توسط این محیط ها به طور مداوم در حال رشد است و خود یک چالش را تشکیل می دهد. روزهایی که یک مهندس میتوانست به سادگی SSH را در یک ماشین قرار دهد و یک فایل log را بگیرد، گذشته است. این کار را نمی توان در محیط های متشکل از صدها کانتینر که روزانه داده های ثبت سل تولید می کنند انجام داد. اینجاست که راهحلهای مدیریت لاگ متمرکز و تجزیه و تحلیل مانند ELK Stack به چشم میخورد که به مهندسان، اعم از DevOps، IT Operations یا SREs اجازه میدهد تا دید مورد نیاز خود را به دست آورند و اطمینان حاصل کنند که برنامهها همیشه در دسترس و کارآمد هستند.راه حل های مدیریت لاگ مدرن و تجزیه و تحلیل شامل قابلیت های کلیدی زیر است:
- تجمیع - توانایی جمعآوری و ارسال گزارشها از چندین منبع داده.
- پردازش - توانایی تبدیل پیام های گزارش به داده های معنی دار برای تجزیه و تحلیل آسان تر.
- ذخیرهسازی – توانایی ذخیره دادهها برای دورههای زمانی طولانی برای امکان نظارت، تحلیل روند و موارد استفاده امنیتی.
- تجزیه و تحلیل - توانایی تجزیه و تحلیل داده ها با پرس و جو و ایجاد تجسم و داشبورد در بالای آن.
نحوه استفاده از پشته ELK برای تجزیه و تحلیل گزارش
همانطور که در بالا ذکر کردم، اجزای مختلف پشته ELK یک راه حل ساده و در عین حال قدرتمند برای مدیریت گزارش و تجزیه و تحلیل ارائه می کنند. اجزای مختلف در ELK Stack به گونه ای طراحی شده اند که بدون تنظیمات اضافی، با یکدیگر تعامل داشته باشند و به خوبی با یکدیگر بازی کنند. با این حال، نحوه طراحی پشته تا حد زیادی در محیط و مورد استفاده شما متفاوت است. برای یک محیط توسعه با اندازه کوچک، معماری کلاسیک به صورت زیر خواهد بود: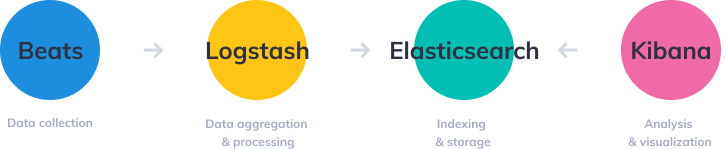 با این حال، برای مدیریت خطوط لوله پیچیدهتر ساخته شده برای مدیریت حجم زیادی از دادهها در تولید، احتمالاً اجزای اضافی برای انعطافپذیری (Kafka، RabbitMQ، Redis) و امنیت (nginx) به معماری لاگ شما اضافه میشوند:
با این حال، برای مدیریت خطوط لوله پیچیدهتر ساخته شده برای مدیریت حجم زیادی از دادهها در تولید، احتمالاً اجزای اضافی برای انعطافپذیری (Kafka، RabbitMQ، Redis) و امنیت (nginx) به معماری لاگ شما اضافه میشوند:
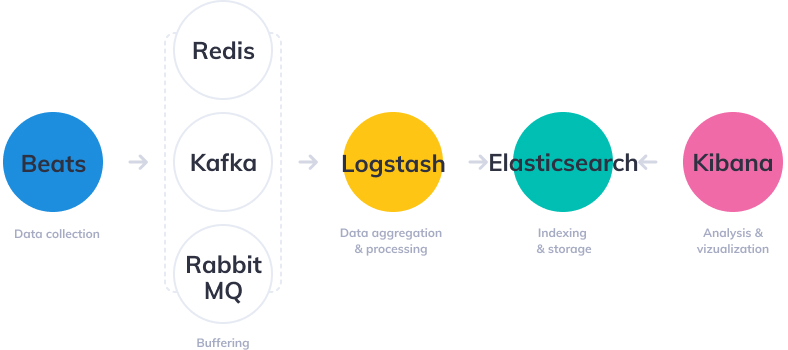
البته این یک نمودار ساده شده برای تصویر است. یک معماری درجه تولید کامل شامل چندین گره Elasticsearch، شاید چندین نمونه Logstash، یک مکانیسم بایگانی، یک پلاگین هشدار و یک تکرار کامل در مناطق یا بخشهایی از مرکز داده شما برای دسترسی بالا است. میتوانید شرح کاملی از آنچه برای استقرار ELK بهعنوان راهحل مدیریت گزارش و تجزیه و تحلیل درجه تولید نیاز است را در بخش مربوطه در زیر بخوانید.
چه خبر؟
همانطور که از یک پروژه متن باز بسیار محبوب انتظار می رود، ELK Stack به طور مداوم و مکرر با ویژگی های جدید به روز می شود. در جریان بودن این تغییرات چالش برانگیز است، بنابراین در این بخش ویژگی های جدید معرفی شده در نسخه های اصلی را ارائه خواهیم داد.
Elasticsearch
راه اندازی Elasticsearch 7.x بسیار ساده تر است زیرا اکنون با جاوا همراه است. بهبودهای عملکردی شامل قطع کننده مدار حافظه واقعی، بهبود عملکرد جستجو و خط مشی 1-شارت است. علاوه بر این، یک لایه جدید هماهنگی خوشه ای Elasticsearch را مقیاس پذیرتر و انعطاف پذیرتر می کند.
Logstash
موتور اجرای جاوا Logstash (که به عنوان آزمایشی در نسخه 6.3 اعلام شد) به طور پیش فرض در نسخه 7.x فعال است. با جایگزینی موتور اجرای Ruby قدیمی، عملکرد بهتر، کاهش استفاده از حافظه و به طور کلی تجربهای کاملاً سریعتر به رخ میکشد.
Kibana
Kibana با صفحات جدید و بهبود قابلیت استفاده، دستخوش تغییرات اساسی شده است. آخرین نسخه شامل حالت تاریک، جستجو و فیلتر بهبود یافته و بهبود Canvas است.
Beats
Beats 7.x با طرح جدید Elastic Common Schema (ECS) مطابقت دارد - یک استاندارد جدید برای قالببندی فیلد. Metricbeat از یک ماژول جدید AWS برای استخراج داده ها از Amazon CloudWatch، Kinesis و SQS پشتیبانی می کند. ماژول های جدیدی در Filebeat و Auditbeat نیز معرفی شدند.
نصب ELK
ELK Stack را می توان با استفاده از روش های مختلف و بر روی طیف گسترده ای از سیستم عامل ها و محیط های مختلف نصب کرد. ELK را می توان به صورت محلی، روی ابر، با استفاده از Docker و سیستم های مدیریت پیکربندی مانند Ansible، Puppet و Chef نصب کرد. پشته را می توان با استفاده از بسته های tarball یا .zip یا از مخازن نصب کرد. بسیاری از مراحل نصب از محیطی به محیط دیگر شبیه هستند و از آنجایی که نمیتوانیم تمام سناریوهای مختلف را پوشش دهیم، نمونهای برای نصب تمام اجزای پشته - Elasticsearch، Logstash، Kibana و Beats - در لینوکس ارائه میکنیم. لینک های دیگر راهنماهای نصب را می توانید در زیر بیابید.
مشخصات محیطی
برای انجام مراحل زیر، ما یک دستگاه AWS Ubuntu 18.04 را روی نمونه m4.large با استفاده از حافظه محلی آن راه اندازی کردیم. ما یک نمونه EC2 را در زیرشبکه عمومی یک VPC راهاندازی کردیم و سپس گروه امنیتی (دیوار آتش) را راهاندازی کردیم تا با استفاده از SSH و TCP 5601 (کیبانا) از هر نقطهای دسترسی داشته باشیم. در نهایت، یک آدرس IP الاستیک جدید اضافه کردیم و آن را با نمونه در حال اجرا خود به منظور اتصال به اینترنت مرتبط کردیم.
نصب Elasticsearch
ابتدا، باید کلید امضای Elastic را اضافه کنید تا بسته دانلود شده تأیید شود (اگر قبلاً بستههایی را از Elastic نصب کردهاید، از این مرحله بگذرید):
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
برای دبیان، باید بسته apt-transport-https را نصب کنیم:
sudo apt-get update sudo apt-get install apt-transport-https
مرحله بعدی این است که تعریف مخزن را به سیستم خود اضافه کنید:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
برای نصب نسخه ای از Elasticsearch که فقط دارای ویژگی های دارای مجوز Apache 2.0 (معروف به OSS Elasticsearch):
echo "deb https://artifacts.elastic.co/packages/oss-7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
تنها کاری که باید انجام دهید این است که مخازن خود را به روز کنید و Elasticsearch را نصب کنید:
sudo apt-get update sudo apt-get install elasticsearch
پیکربندیهای Elasticsearch با استفاده از یک فایل پیکربندی انجام میشوند که به شما امکان میدهد تنظیمات کلی (مانند نام گره)، و همچنین تنظیمات شبکه (مانند میزبان و پورت)، جایی که دادهها، حافظه، فایلهای گزارش ذخیره میشوند، و غیره را پیکربندی کنید. به عنوان مثال، از آنجایی که ما در حال نصب Elasticsearch در AWS هستیم، بهترین روش اتصال Elasticsearch به یک IP خصوصی یا میزبان محلی است:
sudo vim /etc/elasticsearch/elasticsearch.yml network.host: "localhost" http.port:9200 cluster.initial_master_nodes: ["<PrivateIP"]
برای اجرای Elasticsearch از:
sudo service elasticsearch start
برای تأیید اینکه همه چیز طبق انتظار کار می کند، curl یا مرورگر خود را به http://localhost:9200 ببرید، و باید چیزی شبیه خروجی زیر را ببینید:
{ "name" : "ip-172-31-10-207", "cluster_name" : "elasticsearch", "cluster_uuid" : "bzFHfhcoTAKCH-Niq6_GEA", "version" : { "number" : "7.1.1", "build_flavor" : "default", "build_type" : "deb", "build_hash" : "7a013de", "build_date" : "2019-05-23T14:04:00.380842Z", "build_snapshot" : false, "lucene_version" : "8.0.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
نصب یک کلاستر Elasticsearch به نوع دیگری از راه اندازی نیاز دارد. برای اطلاعات بیشتر در مورد آن، آموزش Elasticsearch Cluster ما را بخوانید.
نصب Logstash
Logstash برای اجرا به جاوا 8 یا جاوا 11 نیاز دارد، بنابراین ما فرآیند راه اندازی Logstash را با موارد زیر آغاز خواهیم کرد:
sudo apt-get install default-jre
java -version openjdk version "1.8.0_191" OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.16.04.1-b12) OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
از آنجایی که قبلاً مخزن را در سیستم تعریف کرده ایم، تمام کاری که باید برای نصب Logstash انجام دهیم اجرا می شود:
sudo apt-get install logstash
قبل از اجرای Logstash، باید یک خط لوله داده data pipeline. را پیکربندی کنید. پس از نصب و راه اندازی Kibana به آن باز خواهیم گشت.
نصب Kibana
مانند قبل، از یک دستور apt ساده برای نصب کیبانا استفاده می کنیم:
sudo apt-get install kibana
فایل پیکربندی Kibana را در آدرس زیر باز کنید: /etc/kibana/kibana.yml، و مطمئن شوید که تنظیمات زیر را تعریف کرده اید:
server.port: 5601 elasticsearch.url: "http://localhost:9200"
این پیکربندیهای خاص به Kibana میگویند که به کدام Elasticsearch متصل شود و از کدام پورت استفاده کند.
اکنون کیبانا را با این موارد شروع کنید:
sudo service kibana start
Kibana را در مرورگر خود با http://localhost:5601 باز کنید. صفحه اصلی کیبانا به شما ارائه خواهد شد.
نصب Beats
حملکنندههای مختلف متعلق به خانواده Beats را میتوان دقیقاً به همان روشی که ما سایر اجزا را نصب کردیم نصب کرد.
به عنوان مثال، بیایید Metricbeat را نصب کنیم:
sudo apt-get install metricbeat
sudo service metricbeat start
Metricbeat شروع به نظارت بر سرور شما می کند و یک فهرست Elasticsearch ایجاد می کند که می توانید آن را در Kibana تعریف کنید. اما در مرحله بعدی نحوه راه اندازی خط لوله داده data pipeline با استفاده از Logstash را شرح خواهیم داد.
ارسال مقداری داده
برای هدف این آموزش، نمونهای از دادههای حاوی لاگهای دسترسی آپاچی را آماده کردهایم که روزانه بهروزرسانی میشوند. می توانید داده ها را از اینجا دانلود کنید: نمونه-داده
سپس، یک فایل پیکربندی Logstash جدید در آدرس زیر ایجاد کنید:
/etc/logstash/conf.d/apache-01.conf:
sudo vim /etc/logstash/conf.d/apache-01.conf
پیکربندی Logstash زیر را وارد کنید (مسیر فایلی را که دانلود کرده اید تغییر دهید):
input { file { path => "/home/ubuntu/apache-daily-access.log" start_position => "beginning" sincedb_path => "/dev/null" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } date { match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] } geoip { source => "clientip" } } output { elasticsearch { hosts => ["localhost:9200"] } }
Logstash را اجرا کنید :
sudo service logstash start
اگر همه چیز خوب پیش برود، یک فهرست جدید Logstash در Elasticsearch ایجاد می شود که اکنون می توان الگوی آن را در Kibana تعریف کرد.
در Kibana، به مدیریت ← Kibana Index Patterns بروید. اگر مراحل نصب و اجرای Metricbeat را دنبال کرده باشید، کیبانا باید ایندکس Logstash و همراه با شاخص Metricbeat را نمایش دهد.
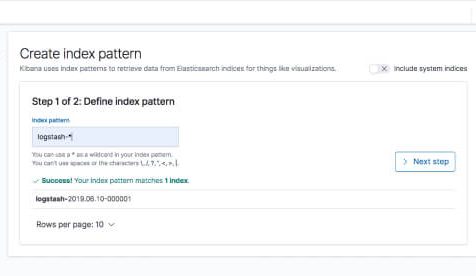
"logstash-*" را به عنوان الگوی شاخص وارد کنید و در مرحله بعد @timestamp را به عنوان قسمت Time Filter خود انتخاب کنید.
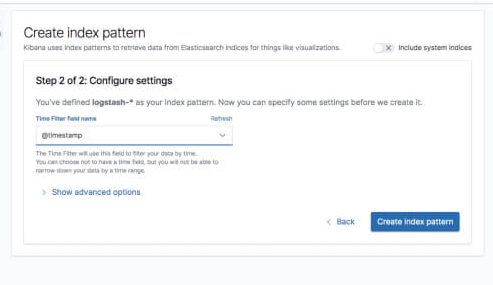
گزینه Create index pattern را بزنید و آماده تجزیه و تحلیل داده ها هستید. به تب Discover در Kibana بروید تا به داده ها نگاهی بیندازید (به جای پیش فرض 15 دقیقه گذشته به داده های امروز نگاه کنید).
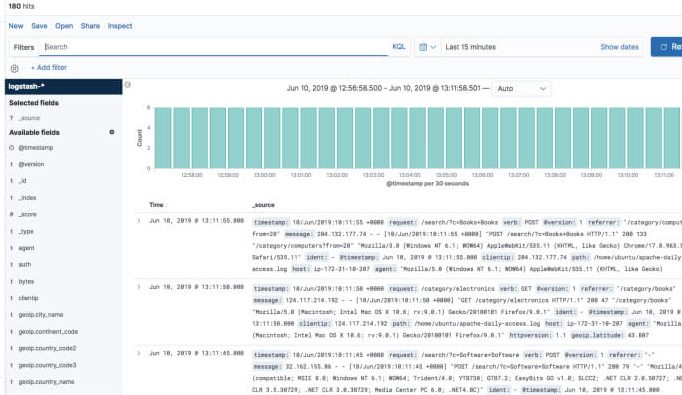
تبریک می گویم! شما اولین خط لوله داده ELK خود را با استفاده از Elasticsearch، Logstash و Kibana راه اندازی کرده اید.
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
در قسمت دوم ساختار الاستیک سرچ را شرح خواهیم داد.
https://enginedevops.com/2022/10/08/what-is-elk-2/
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
منبع: https://logz.io/learn/complete-guide-elk-stack/#installing-elk