راهنمای کامل برای ELK - قسمت دوم
Elasticsearch
ELK چیست؟
Elasticsearch قلب زنده چیزی است که امروزه محبوب ترین پلتفرم تجزیه و تحلیل گزارش در جهان است - ELK Stack (Elasticsearch، Logstash، و Kibana). نقشی که Elasticsearch ایفا می کند آنقدر محوری است که با نام خود پشته مترادف شده است. Elasticsearch که عمدتاً برای جستجو و تجزیه و تحلیل گزارش استفاده می شود، امروزه یکی از محبوب ترین سیستم های پایگاه داده موجود است.
Elasticsearch که در ابتدا در سال 2010 منتشر شد، یک موتور جستجو و تجزیه و تحلیل مدرن است که مبتنی بر آپاچی لوسن است. کاملاً منبع باز و ساخته شده با جاوا، Elasticsearch به عنوان یک پایگاه داده NoSQL دسته بندی می شود. Elasticsearch داده ها را به روشی بدون ساختار ذخیره می کند و تا همین اواخر نمی توانستید با استفاده از SQL از داده ها پرس و جو کنید. پروژه جدید Elasticsearch SQL امکان استفاده از دستورات SQL را برای تعامل با داده ها فراهم می کند. می توانید در این مقاله بیشتر در مورد آن بخوانید.
بر خلاف بسیاری از پایگاههای داده NoSQL، Elasticsearch تمرکز زیادی بر قابلیتها و ویژگیهای جستجو دارد – در واقع، تا حدی که سادهترین راه برای دریافت دادهها از Elasticsearch جستجوی آن با استفاده از REST API گسترده آن است.
در زمینه تجزیه و تحلیل داده ها، Elasticsearch همراه با سایر مؤلفه های ELK Stack، Logstash و Kibana استفاده می شود و نقش نمایه سازی و ذخیره سازی داده ها را ایفا می کند.
درباره نصب و استفاده از Elasticsearch در آموزش Elasticsearch ما بیشتر بخوانید.
مفاهیم اساسی Elasticsearch
Elasticsearch یک سیستم غنی از ویژگی و پیچیده است. جزئیات و سوراخ کردن هر یک از مهره ها و پیچ ها غیرممکن است. با این حال، برخی از مفاهیم و اصطلاحات اساسی وجود دارد که همه کاربران Elasticsearch باید یاد بگیرند و با آنها آشنا شوند. در زیر شش مفهوم «باید بدانید» برای شروع آورده شده است.
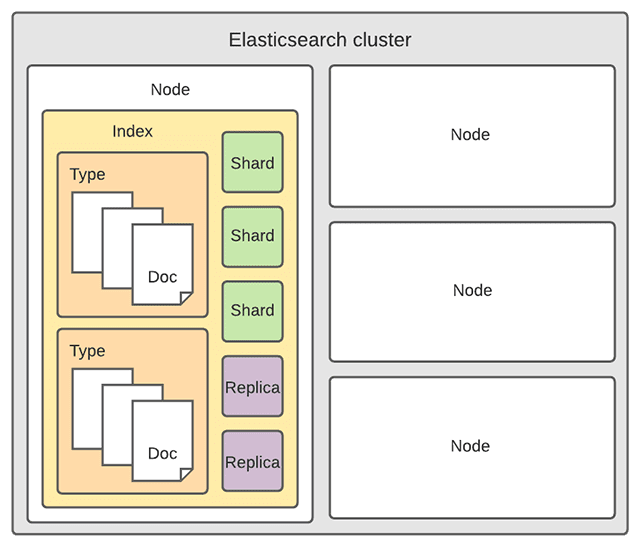
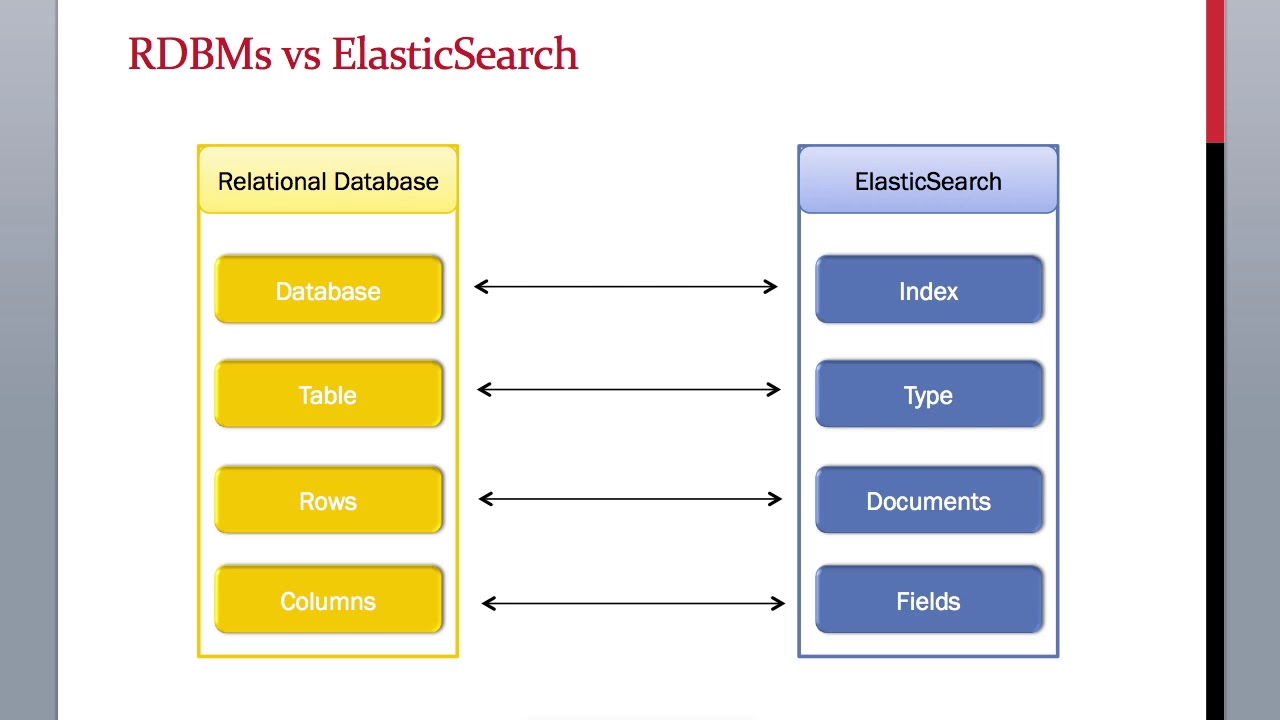
شاخص - Index
شاخص های Elasticsearch پارتیشن های منطقی اسناد هستند و می توانند با یک پایگاه داده در دنیای پایگاه های داده رابطه ای مقایسه شوند.
در ادامه مثال برنامه تجارت الکترونیک ما، میتوانید یک فهرست Index حاوی تمام دادههای مربوط به محصولات و دیگری با تمام دادههای مربوط به مشتریان داشته باشید.
شما می توانید به تعداد دلخواه در Elasticsearch شاخص Index تعریف شده داشته باشید، اما این می تواند بر عملکرد تأثیر بگذارد. اینها به نوبه خود اسنادی را نگه می دارند که برای هر شاخص Index منحصر به فرد هستند.
شاخص Index ها با نامهای کوچک شناسایی میشوند که هنگام انجام اقدامات مختلف (مانند جستجو و حذف) در برابر اسنادی که در داخل هر فهرست هستند استفاده میشوند.
اسناد - Documents
اسناد - Documents اشیاء JSON هستند که در یک فهرست Elasticsearch index ذخیره می شوند و واحد پایه ذخیره سازی در نظر گرفته می شوند. در دنیای پایگاه داده های رابطه ای، اسناد را می توان به یک ردیف در یک جدول مقایسه کرد.
در مثال برنامه تجارت الکترونیک ما، می توانید یک سند برای هر محصول یا یک سند برای هر سفارش داشته باشید. هیچ محدودیتی برای تعداد اسنادی که می توانید در یک فهرست خاص ذخیره کنید وجود ندارد.
داده ها در اسناد با فیلدهایی متشکل از کلیدها و مقادیر تعریف می شوند. یک کلید نام فیلد است و یک مقدار میتواند آیتمی از انواع مختلف مانند رشته، عدد، عبارت بولی، شیء دیگر یا آرایهای از مقادیر باشد.
اسناد همچنین حاوی فیلدهای رزرو شده هستند که فراداده سند مانند _id , _index , _type را تشکیل می دهند.
Types
انواع Elasticsearch در اسناد برای تقسیم بندی انواع مشابه از داده ها استفاده می شود که در آن هر نوع نشان دهنده یک کلاس منحصر به فرد از اسناد است. انواع شامل یک نام و یک نگاشت (به زیر مراجعه کنید) است و با افزودن فیلد _type استفاده می شود. پس از آن می توان از این فیلد برای فیلتر کردن هنگام پرس و جو یک نوع خاص استفاده کرد.
انواع به تدریج از Elasticsearch حذف می شوند. با شروع Elasticsearch 6، شاخص ها می توانند تنها یک نوع نقشه برداری داشته باشند. با شروع نسخه 7.x، تعیین انواع در درخواستها منسوخ شده است. با شروع نسخه 8.x، تعیین انواع در درخواستها دیگر پشتیبانی نخواهد شد.
Mapping
مانند طرحواره ای در دنیای پایگاه داده های رابطه ای، نگاشت انواع مختلفی را که در یک شاخص قرار دارند، تعریف می کند. این فیلدها را برای اسناد یک نوع خاص تعریف می کند - نوع داده (مانند رشته و عدد صحیح) و نحوه فهرست بندی و ذخیره فیلدها در Elasticsearch.
هنگامی که یک سند با استفاده از الگوها نمایه می شود، می توان به طور صریح تعریف کرد یا به طور خودکار ایجاد کرد. (الگوها شامل تنظیمات و نگاشت هایی هستند که می توانند به طور خودکار در یک فهرست جدید اعمال شوند.)
Shards
اندازه شاخص یکی از دلایل رایج خرابی Elasticsearch است. از آنجایی که محدودیتی برای تعداد اسنادی که می توانید در هر فهرست ذخیره کنید وجود ندارد، ممکن است یک نمایه مقداری از فضای دیسک را اشغال کند که از محدودیت های سرور میزبان بیشتر باشد. به محض اینکه یک شاخص به این حد نزدیک شود، نمایه سازی شروع به شکست می کند.
یکی از راههای مقابله با این مشکل این است که شاخصها را به صورت افقی به قطعاتی به نام Shards تقسیم کنیم. این به شما امکان می دهد تا عملیات را در بین Shards ها و گره ها برای بهبود عملکرد توزیع کنید. میتوانید مقدار Shards های هر فهرست را کنترل کنید و این Shards های «index-like» مشابه هم را در هر گره در خوشه Elasticsearch خود میزبانی کنید.
Replicas
برای اینکه بتوانید به راحتی از خرابی های سیستم مانند خرابی های غیرمنتظره یا مشکلات شبکه بازیابی کنید، Elasticsearch به کاربران اجازه می دهد تا از قطعاتی به نام replica کپی تهیه کنند. از آنجایی که کپیها برای اطمینان از در دسترس بودن بالا طراحی شدهاند، به همان گرهای که از آن کپی شدهاند اختصاص داده نمیشوند. مشابه Shards ها، تعداد کپیها را میتوان در هنگام ایجاد ایندکس index تعریف کرد، اما در مرحله بعد نیز تغییر داد.
برای اطلاعات بیشتر در مورد این اصطلاحات و مفاهیم اضافی Elasticsearch، مقاله 10 مفهوم Elasticsearch که باید یاد بگیرید را بخوانید.
پرس و جوها - Elasticsearch Queries
Elasticsearch در بالای Apache Lucene ساخته شده است و نحو پرس و جو Lucene را آشکار می کند. آشنایی با نحو و عملگرهای مختلف آن به شما کمک می کند تا در جستجوی Elasticsearch باشید.
Boolean Operators
همانند بسیاری از زبان های کامپیوتری، Elasticsearch از عملگرهای AND، OR و NOT پشتیبانی می کند:Fields
ممکن است به دنبال رویدادهایی باشید که در آن یک فیلد خاص حاوی عبارات خاصی باشد.
Ranges
میتوانید فیلدهایی را در یک محدوده خاص جستجو کنید،
- age:[3 TO 10] - رویدادهای مربوط به سن بین 3 تا 10 را برمی گرداند
- price:{100 TO 400} - رویدادها را با قیمت های بین 101 و 399 برمی گرداند
- name:[Adam TO Ziggy] - نامهایی را بین آدام و زیگی نشان میدهد
Wildcards, Regexes and Fuzzy Searching
با استفاده از کاراکتر * به جای یک یا چندین کاراکتر یا با استفاده از ؟ به جای یک کاراکتر استفاده کنید.URI Search
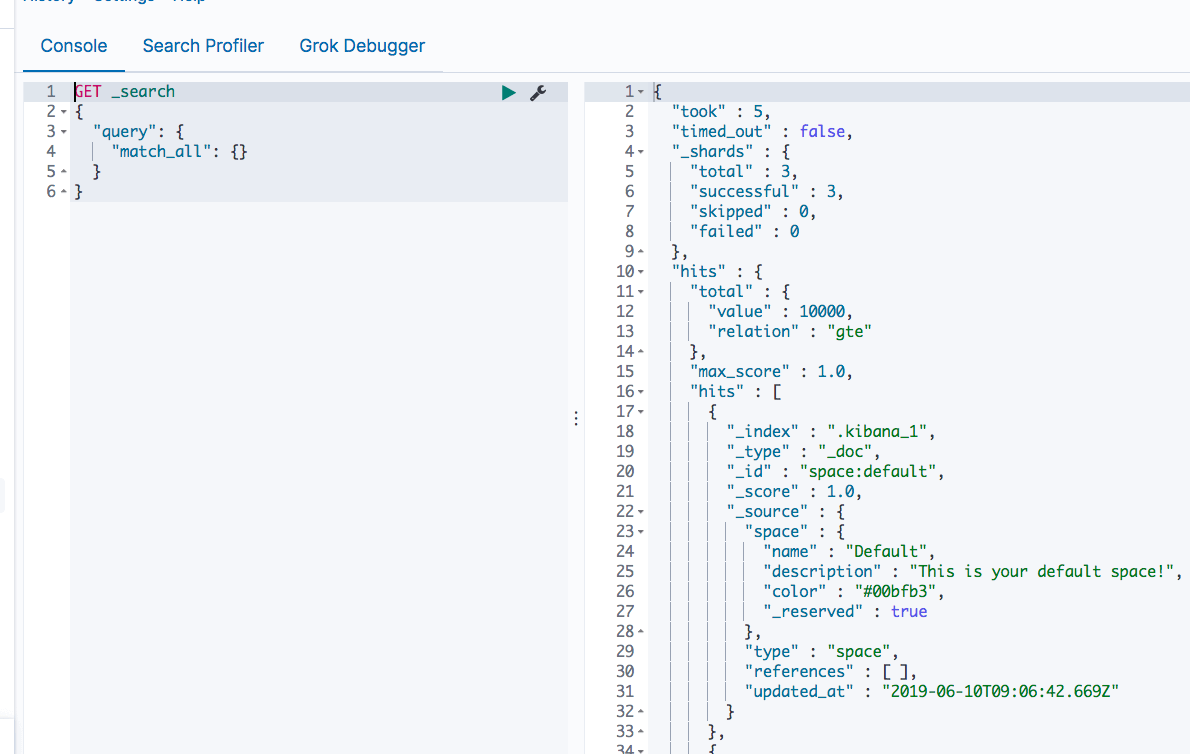
ساده ترین راه برای جستجوی خوشه Elasticsearch از طریق جستجوی URI است. شما می توانید یک پرس و جو ساده را با استفاده از پارامتر q query به Elasticsearch ارسال کنید. پرس و جوی زیر کل خوشه شما را برای اسنادی با فیلد نامی برابر با «تراویس» جستجو می کند:
curl “localhost:9200/_search?q=name:travis”
در ترکیب با نحو Lucene، می توانید جستجوهای بسیار چشمگیری ایجاد کنید. معمولا، شما باید کاراکترهایی مانند فاصله ها را با URL رمزگذاری کنید (برای وضوح در این مثال ها حذف شده است):
curl “localhost:9200/_search?q=name:john~1 AND (age:[30 TO 40} OR surname:K*) AND -city”
تعدادی گزینه در دسترس است که به شما امکان می دهد جستجوی URI را سفارشی کنید، به ویژه از نظر اینکه از کدام تحلیلگر استفاده کنید (آنالایزر)، اینکه آیا پرس و جو باید تحمل خطا داشته باشد یا خیر، و اینکه آیا توضیحی در مورد امتیازدهی باید ارائه شود. توضیح).
اگرچه جستجوی URI یک راه ساده و کارآمد برای پرس و جو کردن خوشه شما است، اما به سرعت متوجه خواهید شد که از همه ویژگی های ارائه شده توسط Elasticsearch پشتیبانی نمی کند. قدرت کامل Elasticsearch از طریق Request Body Search آشکار می شود. استفاده از Request Body Search به شما امکان می دهد با استفاده از عناصر مختلف و بندهای پرس و جو، یک درخواست جستجوی پیچیده بسازید که مطابقت، فیلتر، و ترتیب و همچنین دستکاری اسناد بر اساس چندین معیار باشد.
Elasticsearch REST API
یکی از نکات مهم در مورد Elasticsearch REST API گسترده آن است که به شما امکان می دهد داده های نمایه شده را به روش های بی شماری ادغام، مدیریت و پرس و جو کنید. نمونههایی از استفاده از این API برای ادغام با دادههای Elasticsearch فراوان است که شامل شرکتها و موارد استفاده مختلف میشود.
تعامل با API آسان است – می توانید از هر کلاینت HTTP استفاده کنید، اما Kibana دارای ابزار داخلی به نام کنسول است که می تواند برای این منظور استفاده شود.
به همان اندازه که API های Elasticsearch REST گسترده هستند، یک منحنی یادگیری وجود دارد. برای شروع، قراردادهای API را بخوانید، در مورد گزینههای مختلفی که میتوان برای تماسها اعمال کرد، نحوه ساخت API و نحوه فیلتر کردن پاسخها اطلاعات کسب کرد. نکته خوبی که باید به خاطر بسپارید این است که برخی از API ها از نسخه ای به نسخه دیگر تغییر می کنند و منسوخ می شوند، و این بهترین تمرین خوب است که در مورد شکستن تغییرات توجه داشته باشید.
در زیر برخی از رایج ترین دسته های API Elasticsearch وجود دارد که ارزش تحقیق را دارند. نمونه های استفاده در مقاله Elasticsearch API 101 موجود است. البته، اسناد رسمی Elasticsearch نیز منبع مهمی است.
Elasticsearch Document API
این دسته از APIها برای مدیریت اسناد در Elasticsearch استفاده می شود. برای مثال، با استفاده از این APIها، می توانید اسنادی را در یک فهرست ایجاد کنید، آنها را به روز کنید، آنها را به فهرست دیگری منتقل کنید یا آنها را حذف کنید.
Elasticsearch Search API
همانطور که از نام آن پیداست، از این فراخوانی های API می توان برای جستجوی داده های فهرست شده برای اطلاعات خاص استفاده کرد. APIهای جستجو را میتوان در سطح جهانی، در همه شاخصها و انواع موجود، یا بهطور خاص در یک فهرست اعمال کرد. پاسخ ها حاوی موارد منطبق با پرس و جوی خاص خواهند بود.
Elasticsearch Indices API
این نوع API Elasticsearch به کاربران اجازه می دهد تا شاخص ها، نقشه ها و قالب ها را مدیریت کنند. به عنوان مثال، می توانید از این API برای ایجاد یا حذف یک شاخص جدید استفاده کنید، بررسی کنید که آیا یک شاخص خاص وجود دارد یا نه، و یک نقشه برداری جدید برای یک شاخص تعریف کنید.
Elasticsearch Cluster API
اینها فراخوانی های API مخصوص خوشه هستند که به شما امکان می دهند خوشه Elasticsearch خود را مدیریت و نظارت کنید. اکثر APIها به شما امکان می دهند با استفاده از شناسه گره داخلی، نام یا آدرس آن، تعیین کنید کدام گره Elasticsearch را فراخوانی کنید.
Elasticsearch Plugins
پلاگین های Elasticsearch برای گسترش عملکرد اصلی Elasticsearch به روش های مختلف و خاص استفاده می شوند. به عنوان مثال، افزونه هایی وجود دارند که قابلیت های امنیتی، مکانیسم های کشف و قابلیت های تجزیه و تحلیل را به Elasticsearch اضافه می کنند.
صرف نظر از اینکه چه قابلیت هایی اضافه می کنند، افزونه های Elasticsearch به یکی از دو دسته زیر تعلق دارند: افزونه های اصلی یا افزونه های جامعه. اولی به عنوان بخشی از بسته Elasticsearch عرضه می شود و توسط تیم Elastic نگهداری می شود، در حالی که دومی توسط جامعه توسعه می یابد و بنابراین موجودیت های جداگانه ای با چرخه های نسخه سازی و توسعه خاص خود هستند.
دسته بندی افزونه ها
- API Extension
- Alerting
- Analysis
- Discovery
- Ingest
- Management
- Mapper
- Security
- Snapshot/Restore
- Store
نصب پلاگین های Elasticsearch
نصب پلاگین های اصلی ساده است و با استفاده از یک مدیر پلاگین انجام می شود. در مثال زیر، من قصد دارم افزونه EC2 Discovery را نصب کنم. این افزونه AWS API را برای لیستی از نمونه های EC2 بر اساس پارامترهایی که در تنظیمات افزونه تعریف می کنید، جستجو می کند:
cd /usr/share/elasticsearch sudo bin/elasticsearch-plugin install discovery-ec2
پلاگین ها باید بر روی هر گره در خوشه نصب شوند و هر گره باید پس از نصب مجدد راه اندازی شود.
برای حذف یک افزونه، از:
sudo bin/elasticsearch-plugin remove discovery-ec2
افزونه های انجمن کمی متفاوت هستند زیرا هر یک از آنها دستورالعمل نصب متفاوتی دارند. برخی از افزونههای انجمن مانند افزونههای اصلی نصب میشوند، اما به مراحل پیکربندی Elasticsearch اضافی نیاز دارند.
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
در مقاله بعدی ساختار Logstash را بررسی خواهیم کرد.
https://enginedevops.com/2022/10/08/what-is-elk-3/
منبع: https://logz.io/learn/complete-guide-elk-stack/#elasticsearch